Macro Thesis
Within the past year, we have seen major macro shifts in AI, crypto, hiring, and more. Each of these movements has incited different levels of impulse response from the public. Here, I hope to dive into decentralized training of AI models, a topic, which I personally think has received a much weaker response than it merits. In the next couple of years as communication and compression mechanisms improve, I see two things happening: (1) either I’m wrong and the world continues developing huge centralized clusters or (2) the hypothesis ends up being correct, and we have a major unlock in the amount of available compute for training AI models.
Below, I’ll cover why decentralized AI training makes a lot of sense, discuss some concrete challenges, which currently block it, and then end with a reading
Outline
- Macro Thesis
- Why Decentralized
- What’s holding us back + Exciting Research Shifts
- What’s Next?
Why Decentralized?
- Unlocks a new kind of scale
It’s clear that we are going to keep wanting to train larger and larger models. And as these models scale, so do the data needs for them. However, I would argue that the world isn’t facing a GPU supply problem, rather it’s facing a GPU under-utilization problem.
Let’s run a quick thought experiment. Most modern-estimates agree that around around 48,000 A100s were used to train Llama3 and 25,000 A100s were used to train GPT4 with estimate for training times range from 3 months-12 years. First things first, these are huge jobs and require very careful systems-level engineering from the OpenAI and Meta/FAIR teams to accomplish.
Now, let’s consider a different market: the Ethereum blockchain. At its peak GPU usage in 2022, there were 20–40 million GPUs on the chain, 3 orders of magnitude more than the amount of GPUs used to train Llama 3, one of the largest open source training experiments of all time.
If 1000x available compute doesn’t excite you, I don’t know what will. But as the final nail on the coffin, imagine a world where you train machine learning jobs on your Mac and iPhone. As of 2023, there were over 2 billion apple devices globally. And with major improvements in their GPUs for ML training with MLX and MPS for example, they are becoming serious contenders for ML training and inference. Even tapping into a tiny fraction of this widely distributed network of computation would be game-changing.
2. Nicer Margins
Most people I know like making more and paying less. What if I said decentralization unlocks both?
First, let’s think about why people make more. There are incredible arbitrage opportunities between crypto and AI when it comes to GPUs. On leading chains a Nvidia 4090 might make you $5/day after electricity costs. For AI workloads, the going price of these GPUs is ~$17/day. So if you’re a miner and looking to make extra cash, my very unbiased opinion might be to not mine at all and instead add your compute to Together.ai or vast.ai and start making a lot more money.
Second, let’s consider how costs decrease. Imagine you wanted to train a job, which needs 70 GB of RAM. Normally, I would go get a A100 to avoid the dreaded OOM errors. However, more recently my approach has been slightly different. 3x RTX 4090s stitched together have a much better FLOP/dollar ratio than training a job on these larger devices. Luckily for them, Nvidia has succeeded in preventing people from easily training on the highly efficient 4090s for business reasons. However, this decentralized mechanism would allow us to erect new, much more efficient compound systems for training.
3. New Marketplaces
What does your Mac do when you go to sleep? I guess not much. Now imagine being paid for people in India to train ML models on your computer as you sleep. Maybe a bit scary from a security perspective, but once those kinks are ironed out, I personally am a big fan of earning extra money with zero extra work.
When we consider that most jobs today are memory and not FLOPs bound, it’s quite interesting to think about how 5 16GB Macs connected with fully-sharded-data-parallel support the same memory model as an A100. And once again, the economics are very, very compelling: we’re looking at ~$2/hr for a A100 vs ~$0.60/hr for a fleet of 5 Macbooks. And if you think $0.12/hr per Macbook might not be enough of an incentive for people to let you train on their computers, that’s over $1,000 per year of passive earnings, enough to pay for your mac in under 2 years.
What’s holding us back + Exciting Research Shifts
Decentralized training is really, really hard. I’ll try to decompose this into 2 sub-problems: (1) decentralized training are tricky and (2) networking naturally bottlenecks speed.
- Let’s start with decentralized training methods.
Most individual provisioners of GPUs don’t have huge clusters A100s or H100s connected with Nvlink and InfiniBand. Instead, we’re looking at a heterogenous network of 4090s, Macbooks, etc. scattered across the globe. How do distribute a huge model across these small nodes? Enter data/model parallelism methods.
Given this is meant to be a macro exposition, I’ll keep the technical details brief. However, as a broad overview, you can take a large model and shard into small pieces that can fit on conventional hardware. Below we illustrate how this might work in a fully-shaded data parallel scheme. Essentially, let’s say we have a huge 80GB model. We can chunk the total weights in the model into four sub-pieces each of size 20GB, which can then be scattered across 4 RTX 4090s. Woohoo!! For interested readers, training works by gathering the required weights for a specific layer, executing on it, and then dropping the weights. Thus at any given moment in time, we save on large memory footprints.
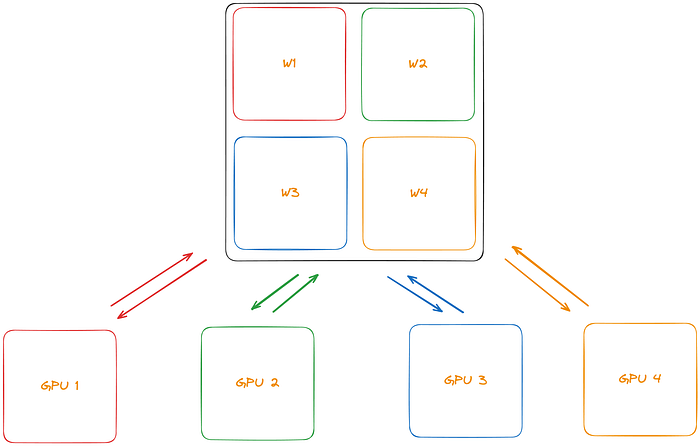
Another design called pipeline parallel, is even more intuitive (and some of you might have already seen it on the Shard demo!). Basically, we just sequentially partition layers of a network onto different devices and they different devices are responsible for different parts of the overall model pipeline — hence the name pipeline parallel. Each device simply communicates to the ones right before and after it in the pipeline, making for an elegant partition overall. Unfortunately, coordinating the bubble and debugging it tends to tricky, so I might suggest starting with fully sharded data parallel, which has more native library support.

2. Communication Bottlenecks. Activations for larger models are on the order of several GBs. This doesn’t matter much when we train on centralized hardware like A100s with internal bandwidths of 2TB/s; however, in a decentralized space, we are relying upon the internet, which, albeit powerful, is much slower.
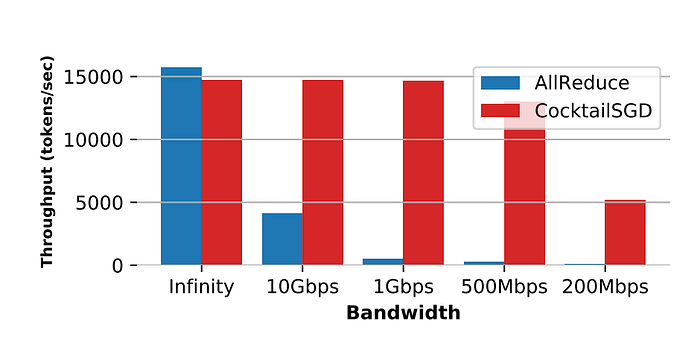
There’s been a ton of really interesting work in this domain such as Distributed Low-Communication Training (DiLoCo), DiPaCo: Distributed Path Composition, Cocktail-SGD, and Fine-Tuning Foundation Models with Slow Network Speeds. Most of these efforts revolve around a mixture of gradient and activation compression, quantization, and random sparsification, with the ultimate goal of reducing the amount of information that has to be shared over these weaked bandwidth internet connections. There’s been very promising strides — for example, Cocktail SGD found only a ~1.2 fold reduction in training speed relative to data-center networks with a 500mbps connection.
What’s Next?
To be honest, the road is a bit unclear. I think decentralized computing is still 2–3 years from being a reality, but that makes it one of those early opportunities to tap into. With Shard, we’re hoping to build out some early tools for easily integrating these solutions and are very excited about the future to come.
