Motivation
Transformers, although powerful, are very compute-intensive, scaling O(n²) in time and memory with the number of tokens. This makes scaling context-windows for modern LLMs very challenging. In Gemma-10M, we merge insights from recurrent neural networks with local attention blocks, to capture long-term knowledge retention with O(1) memory and O(n) time. Thus, our solution allows models to expand to arbitrary context-sizes.
Check us out on:
- Github: https://github.com/mustafaaljadery/gemma-10M-mlx/
- HuggingFace: https://huggingface.co/mustafaaljadery/gemma-10M-safetensor
Outline
- The challenge with standard transformers
- Recurrent Attention
- Infini-Attention
- Incremental context-size training
The Challenge with Standard Transformers
The biggest bottleneck for expanding is the expanding size of the KV-cache, which involves storing the Key-Value pairs in the attention table from prior tokens before computing the attention on the latest token. Not doing so increases the computational cost cubicly, making it almost necessary for longer-sequences. The GIF below illustrates this idea of a KV-cache.
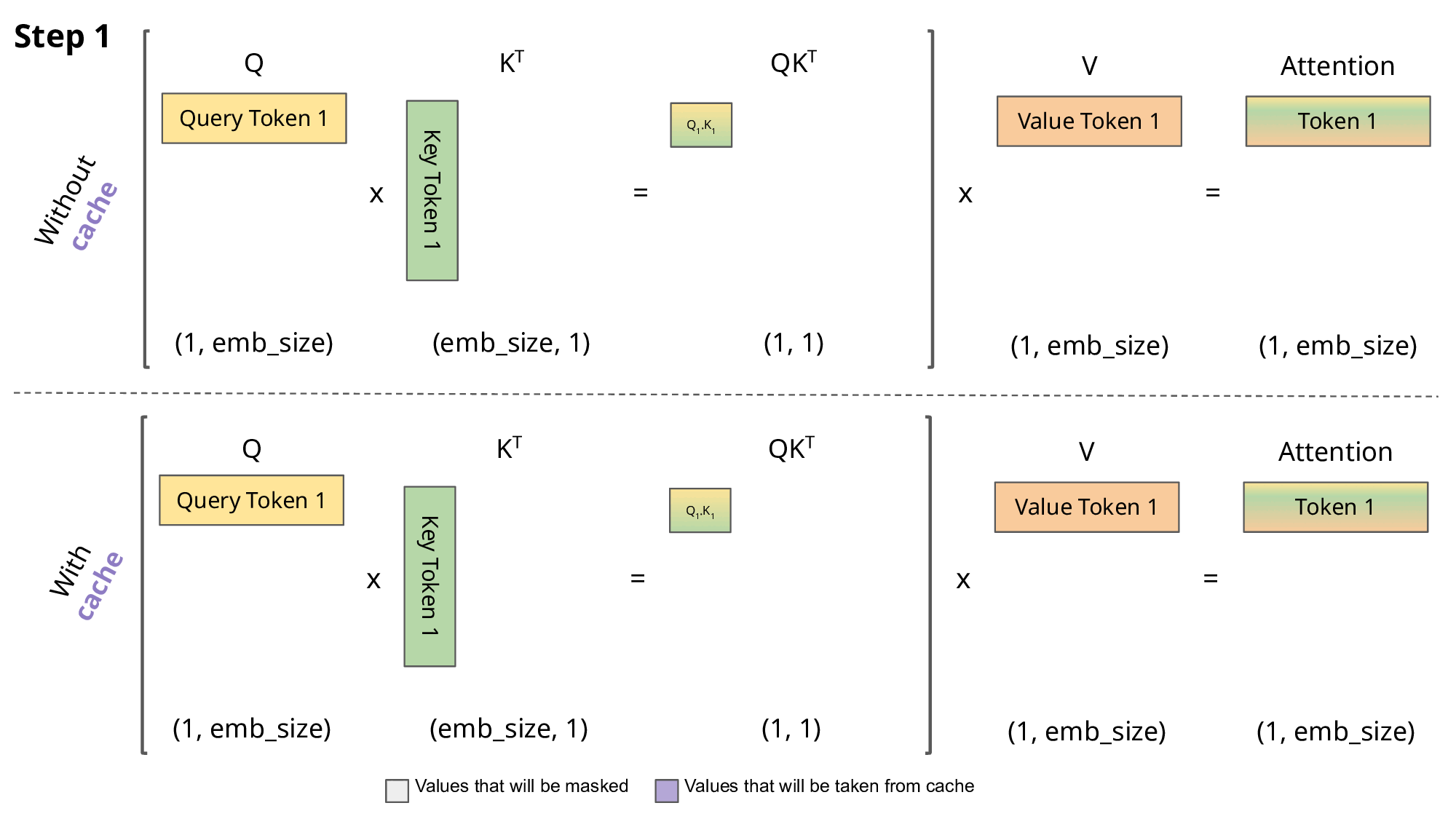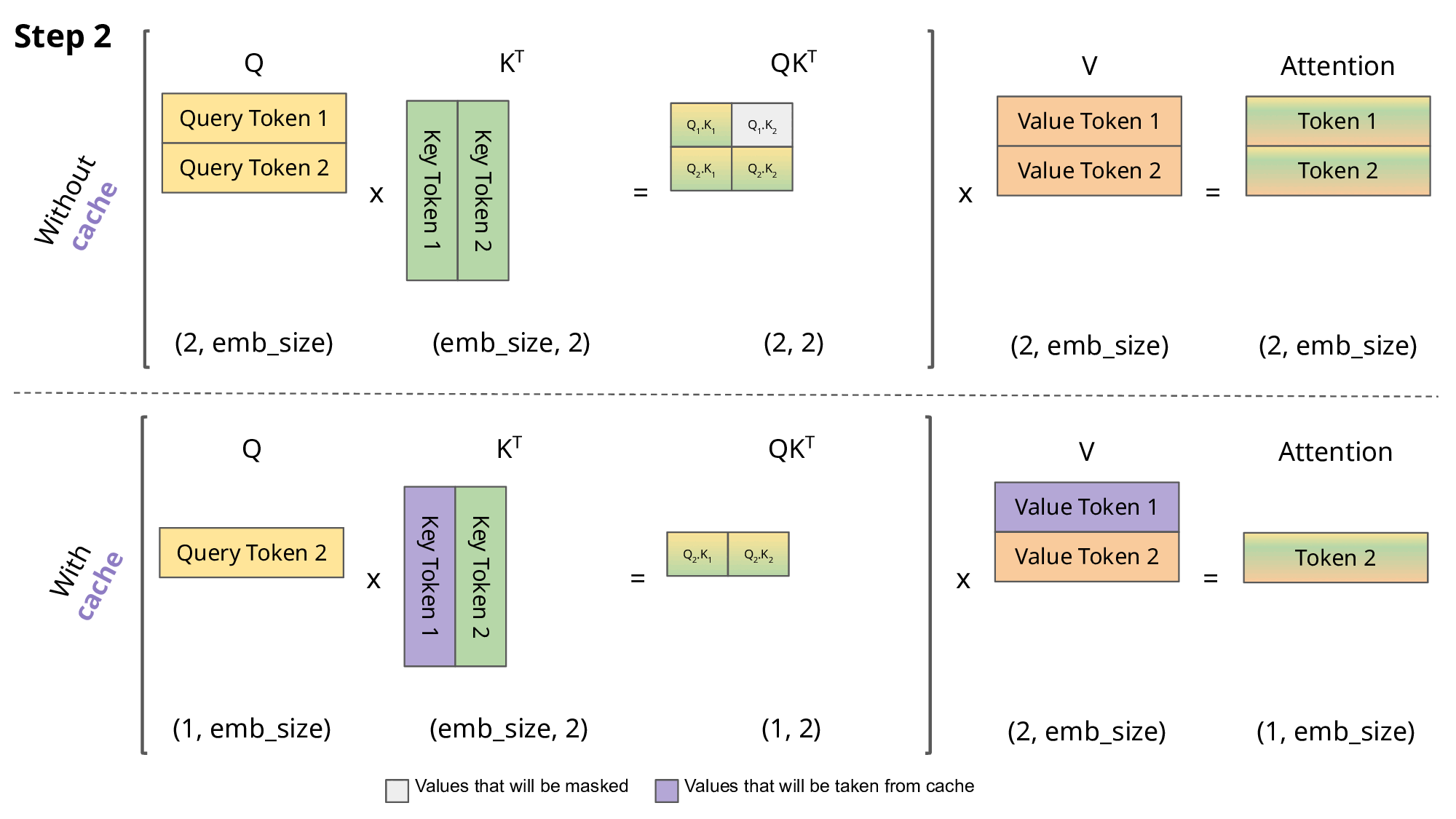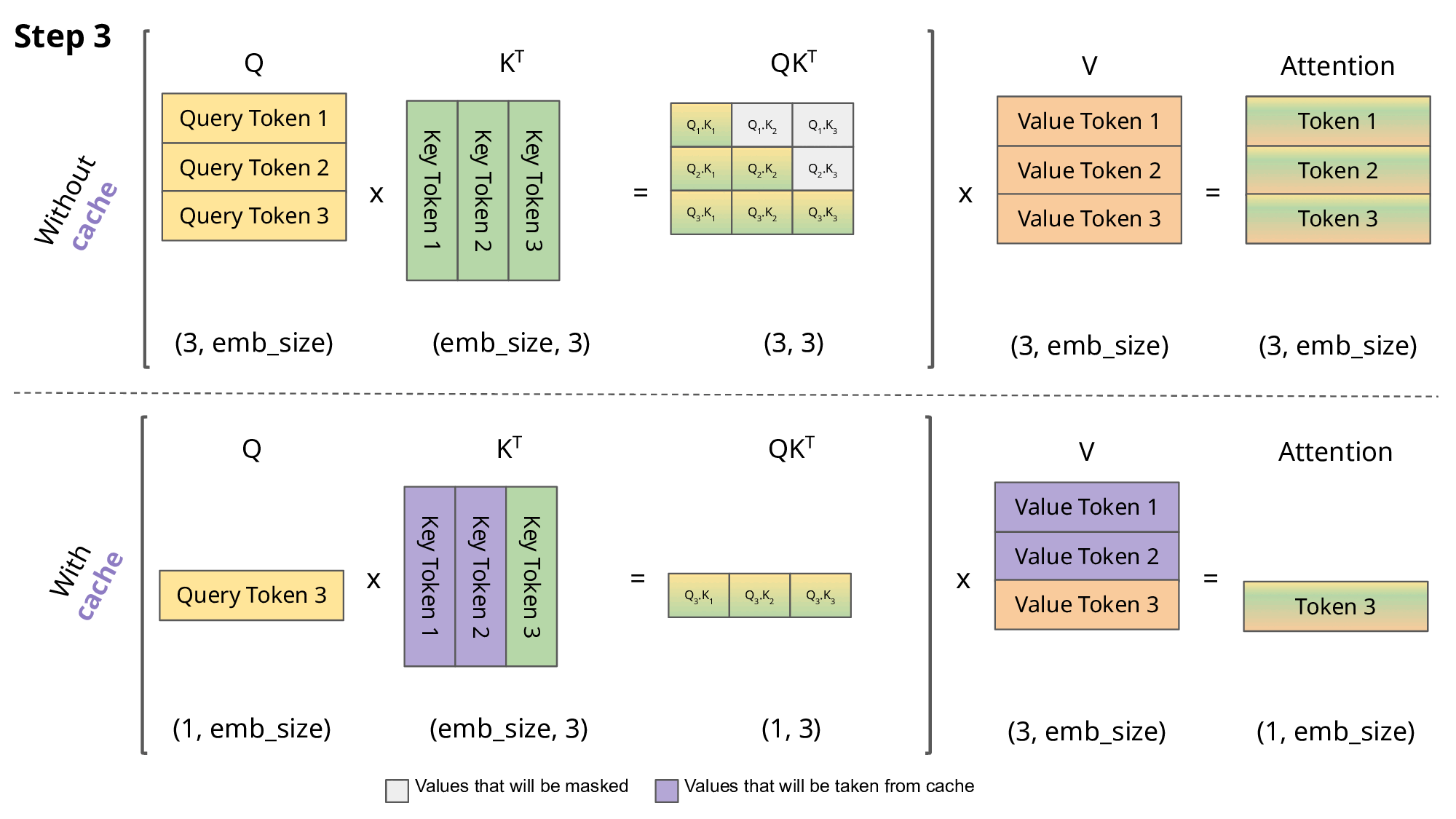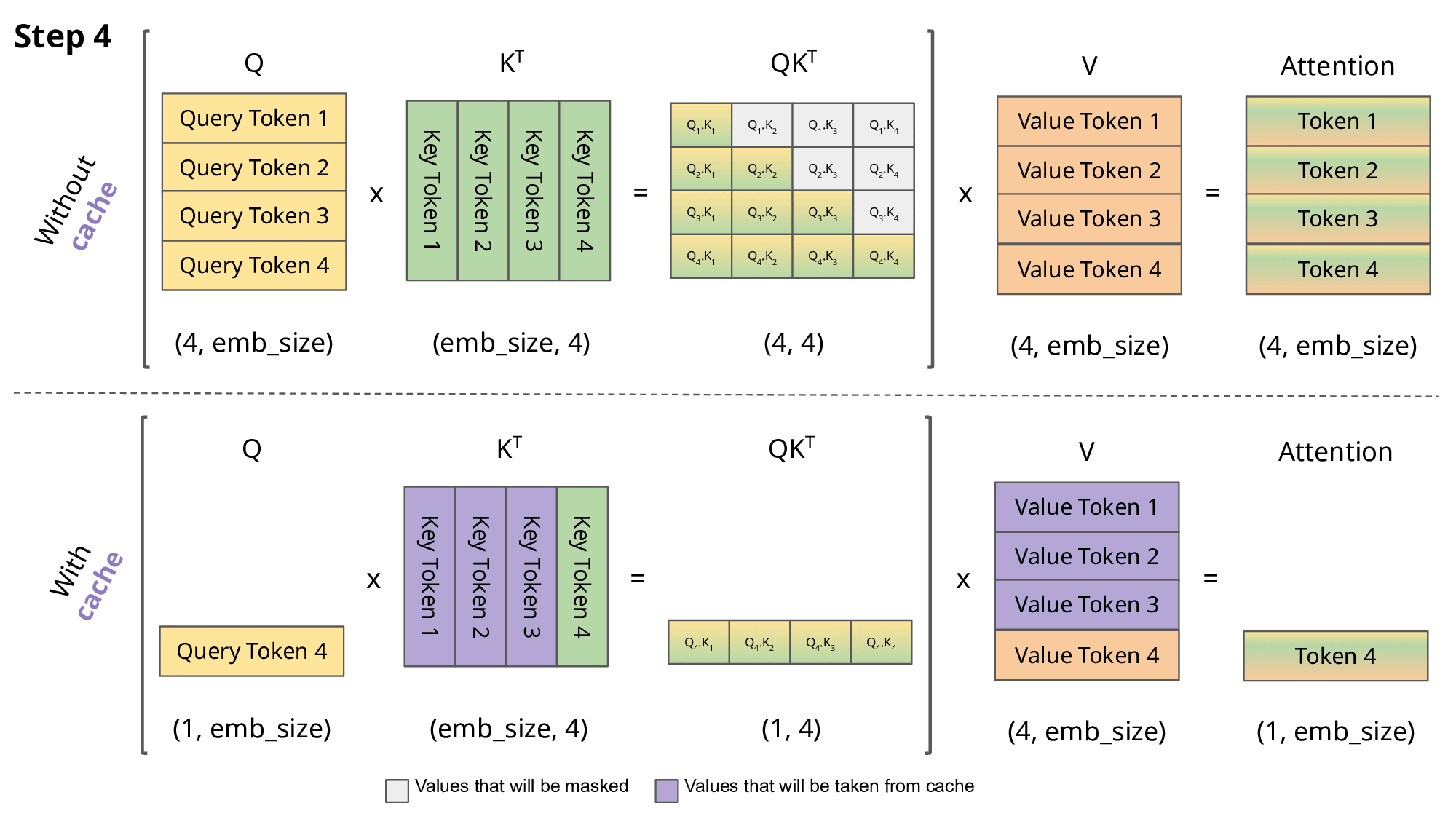
However, storing this cache is expensive — specifically, quadratically so. Especially, when computing attention on contexts lengths of 1M, we are looking at 1,000,000 x 1,000,000 = 12 trillion entries, which we can’t fit in conventional hardware.
Recurrent Local Attention
Borrowing insights from Transformer-XL and recurrent neural networks, we instead compute attention on local 2048 x 2048 blocks and pass that into an MLP to store a state vector. This state vector is then passed as an additional parameter into the next local attention block that we compute, with the goal of preserving memory from earlier in the sequence of tokens.
This schematic is illustrated below. At block 1, our initial state vector is randomly initialized and we compute local attention as normal. This is then passed into an MLP, which computes the next hidden-state vector, retaining memory this layer. As we advance to block 2, we drop block 1 from memory and simply pass its compressed state into the attention module for block 2. At subsequent layers, we repeat this same process, ensuring that only the current attention block and the compressed state from the previous are in memory at any given moment in time.

This unlocks a lot. First, by dropping previous caches, we have no memory overhead with expanding window sizes. Thus, we can fit arbitrarily large context sizes into consumer hardware — which enabled us to run a Gemma 2B-10M model on just 32GB of RAM!
Additionally, we save a lot on inference time. A dense attention block involves computing n² entries. On the other hand, our computation trick decomposes the original matrix into a sparse diagonal block matrix, filling which requires much fewer computations. With an attention block of size d, we have n/d blocks and d² * n/d = nd total parameters. Thus, we go from a total execution flops of O(n²) to O(nd). Especially when n >> d, this reduction is massive and can boost inference, with the caveat that we can’t easily parallelize computations across the whole original matrix.

Infini-Attention
Having established the practicality of a recurrent state vector, let’s dive into some specifics on how our’s works. Borrowing from Google’s seminal Infini-attention paper, we use compressive memory to store information from previous layers. This allows our model to only need to perform standard dot-product (quadratic attention) on our local block and linearly attend to the compressed memory from the past. We illustrate this in the diagram below, where we have standard self-attention to the current Query and Key-Value pairs, as well as cross-attention to the previously cached compressive memory.

This leaves one major question: how does the compressive memory work? The full mathematical details of this are too complex for this blog, but I’ll try to provide you with some intuition. At each layer, we add in a key-value store to our matrix. Thus, at layer 2, our memory matrix M, might look like M0 + v1 k1 + v2 k2. Now, if our keys are orthogonal to one another, we can retrieve the corresponding value associated with a key via a simple dot-product, similar to how coefficients are restored in Fourier-transforms.

But remember, while these simple linear operations generally work, there’s a large graveyard of papers showing that we can’t effectively model softmax(Q K-T) with just a linear matrix multiplications. Therefore, instead of just embedding Q and K into our matrix directly, we instead apply a kernel to both Q and K, with the hope that the softmax operation can be learned as an affine transformation of Q and K in the kernel, σ. This can be a lot to digest, and I find it helpful to think of kernels in terms of how (x+y)² = x² + 2xy + y² are non-linear in both x, y; however, linear in [x², xy, y²]. In this case, our kernel σ. This completes our true update rule for our memory.

Progressively Growing Context Windows
To optimize for training costs and data, we followed the approach in GrowLength, where we gradually increased context size from 32K → 64K → 128K → 256K → 512K → 1M → 2M → 4M → 10M. This allowed us to prioritize pretraining with shorter sequences in the beginning, thereby offering higher utilization rates and allowing us to learn simpler representational embeddings. As the context windows expanded, we then benefited from more powerful initial representational states, which simplified training at larger context-window sizes.

Below, we give a simple example of how this incremental window expansion looks like. At the first layer, our model learns to represent context windows of length up to 32k. Having learned this at layer 1, its task of learning windows of length 64k is made easier as the lower-level representations are already rich. In general, by layer N, the patterns learned by layer N-1 allow us to effectively scale instead of needing to learn complex million token representations all at once. From an algorithmic perspective, this bears semblances to merge sort and dynamic programming, where we learn to solve smaller, simpler problems first, eventually working our way towards larger representations.
Thanks for reading!
If you have any questions, feel free to shoot us an email at
Mustafa Aljadery: aljadery@usc.edu
Aksh Garg: akshgarg@stanford.edu
Sid Sharma: sidshr@stanford.edu
